Improve search ranking for PDF content
30 March 2017
This is the first blog post in a series where we are going to explore how Google ranks PDF documents versus web content created using our upcoming version (version 3.0.1) of FlowPaper Elements. We are going to be completely transparent on how we set up our tests and why we think Google prefers using publications created with FlowPaper Elements as opposed to the PDF so that you can test and verify the results yourself and understand why.
Setting up the test
We decided that we wanted to explore how Google ranked a PDF versus the same content published as HTML5 content. So to do this we staged a little test. We created a blog post with a link to 5 different publications. Each publication converted using FlowPaper Elements and with its corresponding PDF document next to it. You can still see the blog post here. It looks like this:
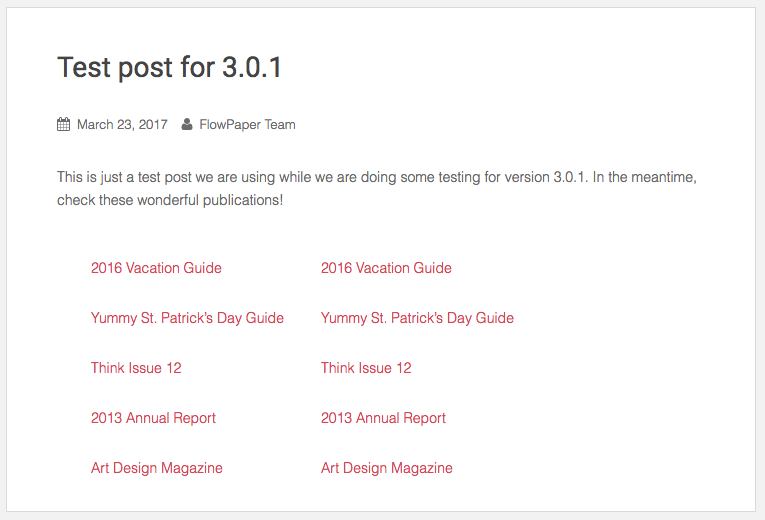
The following assumptions were made around how Google would treat these links:
- Google would treat the PDF and the FlowPaper publication equally on a domain name basis since both are hosted under flowpaper.com. The FlowPaper Elements publication is actually hosted under online.flowpaper.com but Google treats subdomains the same as subdirectories according to themselves. Please see this Youtube link on this.
- Both links were added with absolute positions in the blog post to avoid having Google to rank one better than the other if it appears before the other in the layout
- Google would treat both equally on a file name basis since both had the same file name
Results & Analysis
We allowed a bit more than a week to pass before starting to collect results. We then decided to do 3 different tests to see how Google found content within these links. Main title, sub titles and body text searches. Below are the results of our findings. Note that we appended “site:flowpaper.com” (in italic) to restrict searches within our own domain in case the same publication would appear elsewhere.
Main title searches
FlowPaper was able to outrank the PDF in every case that we tried for main title. Here are the titles searches we performed for the publications:
- 2016 vacation guide site:flowpaper.com (see screen shot)
- 2013 annual report site:flowpaper.com (see screen shot)
- Yummy St. Patricks Day Guide site:flowpaper.com (see screen shot)
- Art & Design Magazine site:flowpaper.com (see screen shot)
- Think Issue 12 site:flowpaper.com (see screen shot)
So how does a PDF define a title compared to a title in FlowPaper? Well, PDFs do not contain meta data around things, so a main title in a PDF is just a larger font that typically appears on the first pages of a document. A main title in FlowPaper Elements on the other hand is an actual header tag (typically a H1 tag) as seen in the screen shot below.
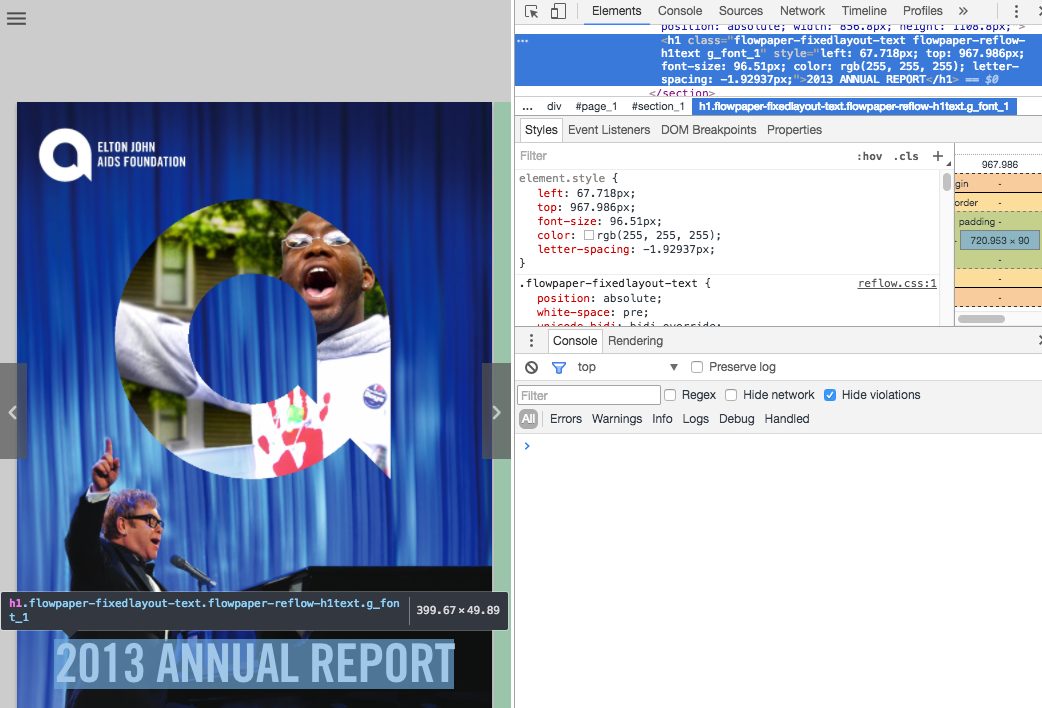
Why is this important? Because according to Google, titles do have relevance to the match of where a certain page lives. FlowPaper Elements make sure that headers are real headers and that they match the title of the publication.
Section title searches
Now thats all fine you might say, because the PDFs may or may not have well defined titles in their text content, so thats a relatively easy thing to beat the PDF on. Well how about titles in sections? Titles in sections should rank high in a PDF too, but there is one major difference in how we treat sub titles and how a PDF treats them. Google claims that having too many titles on the same page would considered crud. Since a PDF contains all titles in the same document, its quite natural to think that a header that appears further down in a document would not get the same search relevance as one on the very top. Let’s have a go and see what happens within our test. We performed the following sub title searches (sub titles marked in bold):
- 2016VacationGuideIndexTest Leland site:flowpaper.com (see screen shot)
- 2013 Annual Report Grants site:flowpaper.com (see screen shot)
- St. Patricks Day Whiskey site:flowpaper.com (see screen shot)
- Design Build site:flowpaper.com (see screen shot)
- think_issue12 Students site:flowpaper.com (see screen shot)
FlowPaper was able to outrank the PDF documents in each and every case of sub title searches we made. How is it possible? Well, just as with the main title, FlowPaper defines each sub section of a publication with a title using a proper HTML5 tag. It also exports each section into its own HTML page and sets the title of the HTML page to correspond with each section as seen in the screen shot below.
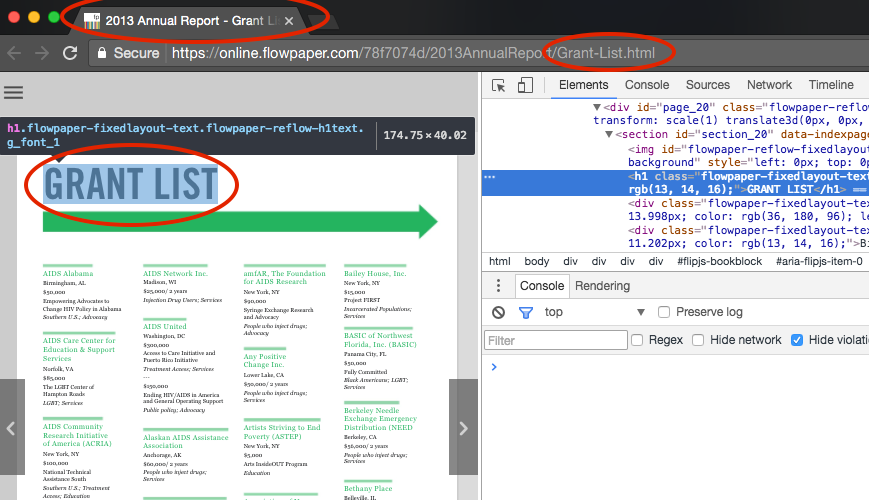
Body Text Searches
So far so good, so how about body texts? A PDF and a FlowPaper publication contains the same body text so these shouldn’t rank differently -right? Well there is one major difference we noted briefly in the previous section. A PDF documents contains all body text in one long page per page structure and FlowPaper splits the document into sections. This means that body text in a sub section would appear higher up in a FlowPaper publication than in a PDF. Lets see what results we’re getting. The body text fragment we searched for is marked in bold.
- 2016VacationGuideIndexTest as with most things on the beach site:flowpaper.com (see screen shot)
- 2013 annual report EJAF and LoveGold site:flowpaper.com (see screen shot)
- St. Patrick’s day guide dancing shoes site:flowpaper.com (see screen shot)
- Selby’s research site:flowpaper.com (see screen shot)
- think_issue12 Thalassaemia site:flowpaper.com (see screen shot)
FlowPaper was able to outrank the PDF in 4 of 5 cases. Number 2 of the tests did not render any Google result from the FlowPaper publication at all (only from the PDF). Whether this was a random fluctuation or why Google for some reason decided to not index that body text is yet unknown. It could be that it will appear in a few weeks.
Conclusions
We have shown that FlowPaper does indeed have the capacity to improve search ranking for your PDF documents while providing accessibility and speed of loading that by far exceeds anything that a normal PDF document can deliver. In our next part we will look at how to avoid getting Google and other search engines to index and save your content using FlowPaper Elements. Keen to get your fingers on our upcoming version? Contact us via email and we’ll send you a pre-release!